




Machine Learning is an exciting territory. It's the gateway for a plethora of possibilities, there is so much to explore, to experiment with and also, to learn. What some beginners miss out on amongst all the learning is the practicing. Machine learning concepts HAVE to be applied on real-world projects for any beginner to gain a better understanding of them. If you ask me, projects are better teachers. But sometimes, it gets really hard to choose a project to work upon, so how should we do that? The key to finding a good project is by selecting the perfect dataset, because if your dataset is complicated, or lacks the needed information, the entire project will become a nightmare.
Now, where can we find this "perfect dataset"? The answer is, Kaggle. If you are unfamiliar, Kaggle, is an online community of data scientists and machine learning practitioners and is perhaps the largest, and most popular website for datasets. It supports a variety of dataset publication formats but not all of them are "good". In fact if you are a beginner, almost all of them will be incomprehensible for you. So, here we have a list of top 10 absolutely beginner-friendly datasets on Kaggle, that you could use to make some amazing projects. (Click on the title to get redirected to the dataset! )
1. Titanic - Machine Learning from Disaster

This is inarguably one of the best datasets to begin with. You get to learn a lot and also get familiarized with the Kaggle platform whilst working on this one. The problem statement is simple: use machine learning to create a model that predicts which passengers survived the Titanic shipwreck. Since, this is the best dataset for beginners they also have a video to guide you on how to get started. If you like your model, you can also submit it in the Kaggle competition too!

We all know that Netflix is amazing, but in the middle of a late-night Netflix binge session have you ever wondered exactly how many shows has Netflix produced till date, or that how many of them are "teenage dramas", or if Netflix has actually reduced their movie duration over the past 10 years? I know I have. This a great dataset because it allows you to get creative and play with your curiosity. You use your skills as a budding data scientist to find the answer of questions you have wondered about, or plot graphs to see what are the top 10 languages Netflix creates the most content in.

The Iris flower data set is a very popular dataset, often used to learn multi-class classification. The problem statement here is that Given Sepal and Petal lengths and width we need to predict the class of Iris. Don't worry if this seems intimidating at first, if you review the dataset once, and try to work on it, you might actually be able to solve the problem statement .

This is again, one of the most preferred dataset by all beginners. It is quite large and contains 79 explanatory variables describing (almost) every aspect of residential homes in Ames, Iowa. The problem statement for this is to Predict the final price for each home. You will have to review all the columns, find the ones that are needed and drop the rest. You can also try to find a correlation between some of the parameters that might have a higher effect on price.

The datasets describe ratings and free-text tagging activities from MovieLens, a movie recommendation service. But with so many movies available these days, it has become a herculean task to find the one that is perfect for our taste. New programmers can actually work on this dataset to develop a Machine Learning model that can recommend movies according the user's previous choices. The datasets describe ratings and free-text tagging activities from MovieLens, a movie recommendation service.

This is quite a bug dataset that contains information on default payments, demographic factors, credit data, history of payment, and bill statements of credit card clients in Taiwan from April 2005 to September 2005. While there is no problem statement for it, but as a test of skills you can try to find the correlation between default payment probability and demographic variables.
 This dataset can be used to understand how useful Machine Learning can be in saving lives. An early diagnosis of Breast Cancer can greatly improve the prognosis and chance of survival for patients, and using this dataset we can actually try and identify the malignant tumors, by classifying tumors as Benign or Malignant based on the tumor shape and its geometry.
This dataset can be used to understand how useful Machine Learning can be in saving lives. An early diagnosis of Breast Cancer can greatly improve the prognosis and chance of survival for patients, and using this dataset we can actually try and identify the malignant tumors, by classifying tumors as Benign or Malignant based on the tumor shape and its geometry.
Another example of use of Machine Learning in the medical field. In this dataset, we can classify our dataset in order to check if a patient might have heart diseases or not. The best approach is to use Logistic Regression (classification) algorithm for it.
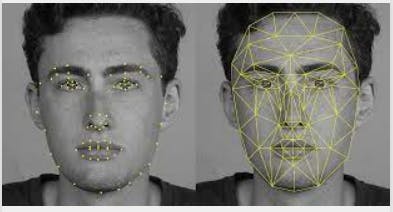 Now this is not exactly a beginner-friendly dataset. But once you have worked on all the previous mentioned datasets and wish to test yourself or experiment with the pretty exciting field of Computer Vision, this is the best option. The objective of this task is to predict keypoint positions on face images. This technology has a lot of uses like, face recognition, image tracking, medical diagnostics, etc. That being said, this can be a quite challenging task.
Now this is not exactly a beginner-friendly dataset. But once you have worked on all the previous mentioned datasets and wish to test yourself or experiment with the pretty exciting field of Computer Vision, this is the best option. The objective of this task is to predict keypoint positions on face images. This technology has a lot of uses like, face recognition, image tracking, medical diagnostics, etc. That being said, this can be a quite challenging task.
10.Bag of Words Meets Bags of Popcorn
 Now, this dataset is for beginners in Natural Language Processing, or NLP. NLP is solely concerned with the interactions between computers and human language, in particular how to program computers to process natural language data. Hence this is not a beginner task per say. But, this dataset is definitely beginner-friendly for intermediate Machine Learning Programmers who are willing to venture into Deep learning. As a beginner this will help you understand basic NLP techniques and build skills for Deep Learning.
Now, this dataset is for beginners in Natural Language Processing, or NLP. NLP is solely concerned with the interactions between computers and human language, in particular how to program computers to process natural language data. Hence this is not a beginner task per say. But, this dataset is definitely beginner-friendly for intermediate Machine Learning Programmers who are willing to venture into Deep learning. As a beginner this will help you understand basic NLP techniques and build skills for Deep Learning.
Now that you know what all datasets to work on, hurry and get working!